
About
As a Data Engineer with 5 years of professional work experience, I excel in building robust and scalable big data systems to automate analytical processes and deliver business critical data products.
During my industry experience, I have siginificantly worked on the design and development of batch and streaming data pipelines, with a focus on modernizing legacy data systems, scalability, and data quality. This has helped me gain substantial exposure to various big data technologies on cloud-native (AWS/GCP) environments. Additionally, I have developed a solid foundation in problem-solving, distributed processing, data modeling, data governance, and automating ETL flows using data orchestration tools. I also enjoy exploring practical applications of AI in data workflows, from classisfication use cases to improving developer productivity.
Further, I love sharing my knowledge and contributing to the data engineering community through my technical writing. I have authored various Medium articles talking about my learning and experiences. Additionally, I serve as an Editor for Data Engineer Things publication which is dedicated to curating original learning resources for data engineers on Medium platform.
Work Experience
CVS HealthIrving, Texas
Data EngineerMay 2024 - Present
CVS Health is a leading healthcare company integrating pharmacy, insurance, and care delivery, and I am part of its health insurance subsidiary, Aetna. As a Data Engineer in pricing and optimization analytics team, my focus is on building data products to support Aetna business in identifying fraudulent insurance claims and save millions in costs.
- Own and manage critical medical claims pipeline with 4.5B+ rows refreshed daily through complex data integration process; lead schema updates, process optimization, and act as SME for business stakeholders.
- Leveraged healthcare-tuned MedLM Gen AI model and implemented parallel asynchronous data processing on 10M+ historical overpaid insurance claims, enabling AI-driven fraud detection.
- Engineered a complex data parsing pipeline for high-volume API data, performed advanced joins to combine data from multiple sources, building critical dataset for revenue calculations worth $15M annually.
- Developed BigQuery cleanup workflow to save ~$20K in monthly storage costs across multiple GCP projects.
LaceworkMountain View, California
Data Engineer InternMay 2023 - August 2023
Lacework is a developing company in the cloud security space offering robust security solutions to protect modern cloud environments from advanced threats and vulnerabilities. During the internship, I was part of the sole data engineering team and I worked on building core datasets, enabling data-driven decision-making on Lacework's product improvements.
- Built a core dataset to enable Lacework product usage analytics, driving 70% reduction in Snowflake storage requirements and saving $30K in monthly Fivetran costs by replacing high-cost legacy jobs..
- Deployed automated Airflow pipelines on AWS, leveraging advanced API querying techniques in Python to ingest data from an observability platform, achieving 100% data quality and completeness.
Target CorporationBengaluru, India
Senior Data EngineerJune 2021 - July 2022
At Target, one of the largest retailers in the world, I worked for three years. As a Senior Data Engineer, I was part of Space Presentation and Transitions team. In this role, I built optimized data processing systems to integrate and deliver certified data products that helped Target drive decisions regarding space planning and optimization in retail stores, inventory allocation, store remodeling, and planogram transitions.
- Spearheaded migration of 8 SQL-based legacy data pipelines into modern data systems by employing Spark and Scala framework on Hadoop platform, boosting overall operational efficiency by 40%.
- Optimized retail items batch data pipeline processing 800M+ records by using Spark to save 3 hours of runtime.
- Developed GraphQL-based API to query data from PostgreSQL database and eliminate dependency on a time-intensive reporting tool, reducing downstream data consumption duration by 60%.
Data EngineerJuly 2019 - May 2021
In this role, I was part of Guest Marketing team, and built end-to-end data pipelines to integrate Target's marketing campaign data that ultimately helped the advertising and financing team to understand the business impact of marketing campaigns run through various social media channels.
- Designed unified data ingestion model for 5 core datasets, eliminating redundancy and saving 4 hours of ETL time.
- Collaborated with data scientists and product managers to deploy Kafka-based streaming data pipelines for 4 social media channels, enabling cross-functional teams to make agile marketing decisions.
- Developed Grafana dashboards for real-time monitoring of data pipelines, incorporating data quality checks and anomaly detection processes, resulting in a 50% decrease in SLA for issue resolution.
- Established CICD best practices and built an artifact of data transformation utilities, reducing time-to-production.
Wells FargoBengaluru, India
Data Analyst InternMay 2018 - July 2018
- Performed historical analysis of pilot program data to determine business impact by deriving 6 efficiency metrics.
- Derived insights using advanced SQL and recommended strategies to grow program revenue by 10%.
Education
Texas A&M UniversityCollege Station, Texas
Master of Science in Management Information SystemsAugust 2022 - May 2024
Relevant Coursework: Advanced Database Management, Data Wareshousing, Data Analytics and Machine Learning, System Analysis and Design
Academic Experience: Graduate Assistant for "ISTM210 - Fundamentals of Information Systems" course
National Institute of Technology KarnatakaSurathkal, India
Bachelor of Technology in Computer Science and EngineeringJuly 2015 - May 2019
Relevant Coursework: Software Engineering, Database Management Systems, Design and Analysis of Algorithms, Operating Systems
Organizations: Artists' Forum, Student Hostel Council
Projects
Explore my data engineering projects in this section.
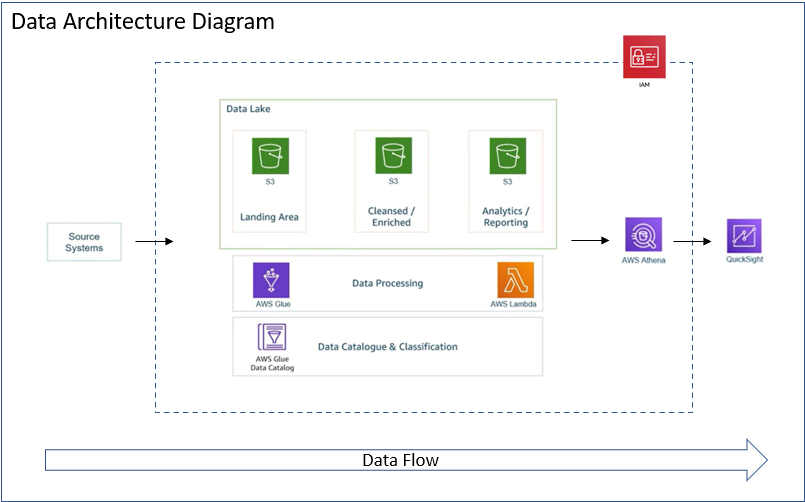
AWS ETL Pipeline on YouTube Data Code
Tech Stack: AWS, Python, Spark
Designed and implemented a data architecture using AWS services. Built end-to-end data pipeline by utilizing S3 for storage, Lambda, Spark, and Athena services to transform and analyze YouTube trending videos dataset containing 1M+ rows. Orchestrated the ETL workflow in GLue Studio and created QuickSight dashboards to visualize key metrics.
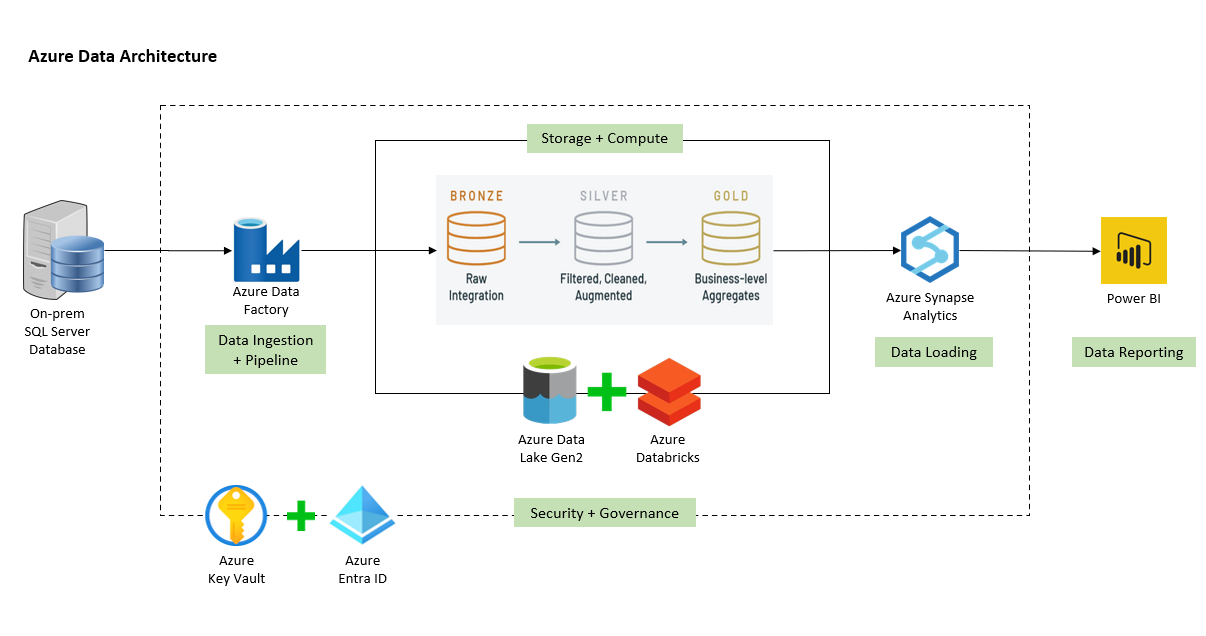
Database Migration Azure Data Engineering Code
Tech Stack: Azure, SQL Server, Python
Migrated on-premises SQL Server AdventureWorks database to Azure Cloud. Authored automated data pipeline using Azure Data Factory for data transfer, Azure Databricks for data transformation, and Azure Synapse Analytics for efficient data querying and reporting needs. Built Power BI dashboards to visualize key metrics and display product and sales insights.
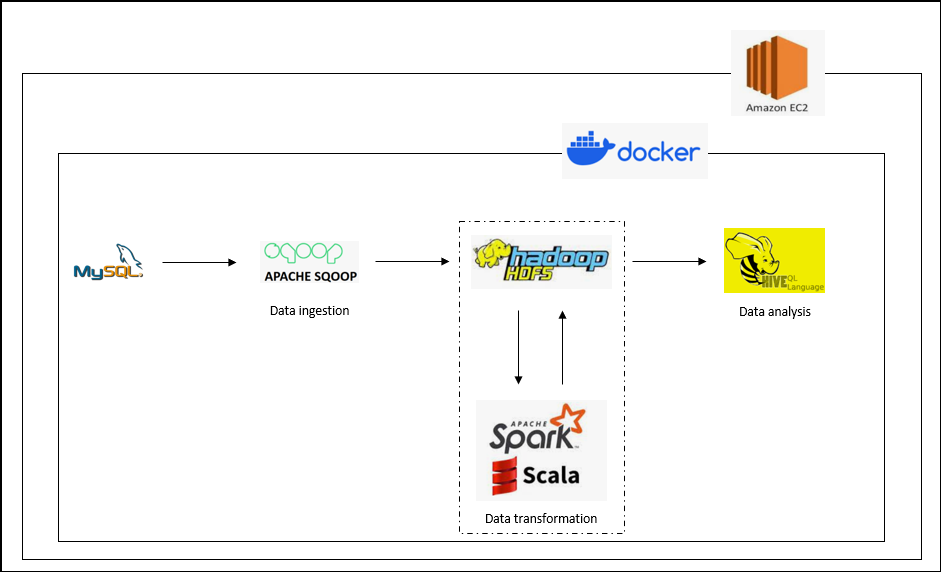
Hive Analytical Platform on AWS Code
Tech Stack: AWS, Docker, MySQL, Scala, Spark, Hive
Built a Hive data warehouse hosted within Docker containers on AWS EC2 instances to effectively manage and analyze e-Commerce data. Utilized data management tools like Sqoop for data extraction and loading, Spark for data processing, and custom shell scripts for automation. Extracted valuable insights regarding sales and customer behavior by using HiveQL for querying.
Blog
Explore my technical articles on data engineering in this section.
Skills
Here is a snapshot of data engineering skills that I bring to the table.
Programming Languages
- Python
- SQL
- Scala
- Java
- Shell-scripting
Big Data
- Snowflake
- Hadoop
- Spark
- Kafka
- Airflow
- Oozie
Databases
- MySQL
- PostgreSQL
- MS SQL
- HBase
- NoSQL (MariaDB)
Visualization and Other Tools
- Grafana
- Power BI
- Advanced MS Excel
- Git
- Jira
Cloud and Containers
- AWS (S3, EC2, Glue, Athena, Lambda, EMR, IAM)
- GCP (BigQuery, Composer, Dataproc, GCS, Cloud Spanner)
- Azure (Data Factory, Data Lake, Databricks, Synapse Analytics)
- Docker/Kubernetes
Contact
Feel free to reach out to me on the details mentioned below.
Write to me: shivananda199@gmail.com